
At Pisano, we sell a solution for businesses to collect feedback from their customers, engage with them in real time, and analyze results.
One of the core feature of our product is the “analyze” part where we offer reporting. Here is what it looks like:
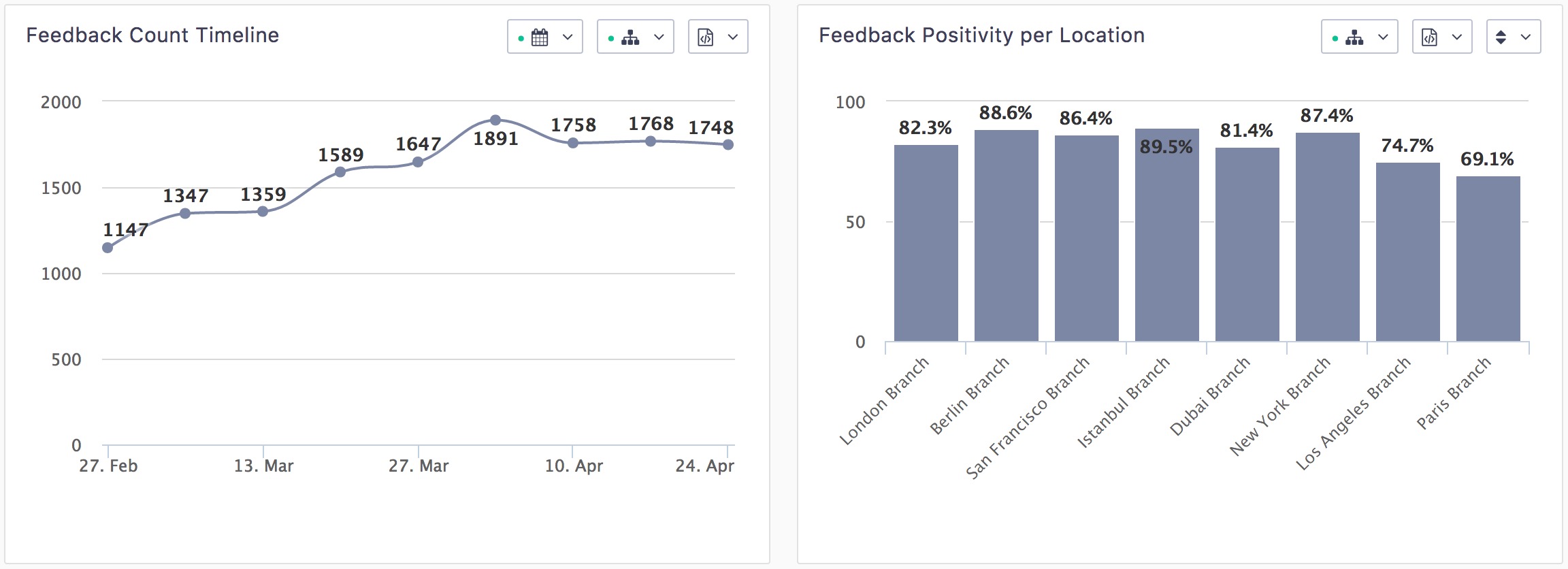
From a technical perspective, those reports are a bunch of clever queries of our PostgreSQL database: joining a few tables, filtering, grouping, and decorating results for display. It has served us well as long as we were collection a few thousand feedbacks per months.
We started to hit a performance problem as we acquired more and more customers who became bigger and bigger. Thus our reporting endpoints became slower and slower. Indeed, joining tables with millions of rows is exponentially more expensive than joining tables with a few thousand rows.
The specifications
So the developers team gathered to find a solution. We had a few criteria:
- It should improve the performance so that request duration is “reasonable” (what reasonable means would have to be defined).
- It should not take too much of developer time to implement: we are a small team of 3 full time developers + 2 part time developers for the entire product, we can’t spend all of our time for this.
- Consequently, it should be maintainable by our small developers team.
Then we did some research for a solution.
The big thing we quickly stumbled upon is, as with many things in programming: it’s all about trade offs. At a certain scale, you can’t have it all:
❌ Fast
✅ Real time reporting
✅ For any custom statistic
✅ For data from any time period
We had all of that except “Fast”. So there needed some business decisions here: what do we trade for faster reporting? What is the business’s priority? Here are the possible trade offs:
✅ Fast
✅ Almost real time reporting
✅ For a limited range of custom statistic
✅ For young-ish data
Whatever we chose, there would be a synchronization time between storing tables and the reporting table. So that would be our first trade off: no more “Real Time” reporting. We can still have acceptable Almost Real Time data by synchronizing often.
The business decision was to try to keep “any custom statistic” as a priority.
Choosing a Reporting infrastructure
The idea is to limit the time spent in the Database. As we want to keep “any custom statistic” (our customers can create their custom reporting widgets for the statistic they need), we don’t have a lot of margin on the “filtering and grouping” parts. But we can drastically reduce the joining time by not joining tables at all: We would need a denormalized table that contains all the needed data, that we can filter and group according to the requested report.
Failed try: MongoDB
We considered using a non-relational Data storage to denormalize our Data. We picked MongoDB but after some trials, we evaluated the followings:
👍 It is possible to denormalize any kind of Data.
👎 It is complex to synchronize Data between PostgreSQL and MongoDB: it requires complex logic and background jobs. Those are prone to failures and timeout.
👎 Querying a MongoDB storage in Rails can be done with the Mongoid ODM, but it’s a new thing to learn. Even worst: it looks like ActiveRecord, but it’s not. That could cause much headache to future us, or future developers.
Successful try: PostgreSQL Materialized Views
The next solution we tried was PostgreSQL Materialized Views.
In a nutshell, a Materialized View (or “matview”) is a database object that contains the results of a query. This has some advantages: the stored results work like a regular Database table, so even if the generation of the matview is expensive, querying the matview itself will be as fast as querying a regular table. Additionally, a matview can be indexed, which will also make queries faster.
There are also disadvantages: the data stored in the matview is not dynamic and need to be refreshed: You have to know when to refresh. And it can be CPU consuming to refresh one matview, let alone several of them.
For us it came up like a good solution:
👍 It is a good fit with our data structure and the kind of reporting we offer. We would need 3 denormalized tables as matviews and we would not need to join them, except in a very rare edge case.
👍 There is no synchronization as everything stays in the same Database. Refreshing Data is very robust (one Database instruction), even though CPU consuming.
👍 As a materialized view is really just another table, we can query it with ActiveRecord. That’s great for our developer productivity: we don’t have to learn another query language or ORM/ODM, it’s just our standard SQL and ActiveRecord.
But is it any fast? Even denormalized, our 3 matviews would be several million rows each. The performance was improved but not enough.
Because of that, we went for a second trade off: we would keep only 90 days of data in the matviews, as it covers most of our customers need anyway. This would reduce the table size and make filtering and grouping faster.
If our customers need reporting for data older than 90 days, which happens only occasionally, it’s ok if they have to wait longer for the results.
With this period limitation, we now have acceptable performance.
Implementation Example of a matview with scenic
It’s pretty straightforward to use PG matviews with Ruby on Rails. There are a few tutorials on the mighty Internet on how to do that. However, in a standard implementation, Database views don’t appear in the schema.rb file.
We would prefer if they appeared in the Schema, so we decided to use the scenic gem. There are a few other nice perks for using scenic as you will see in the following example.
Here are the steps after having installed scenic:
Step 1: Generate a new scenic model
Scenic provides a generator:
$ rails generate scenic:model report_feedback --materialized
This will generate a migration, a new empty SQL file to write the query, as well as an ActiveRecord Model and it’s test file.
The model includes a refresh class method that we will update to have concurrent refreshing, which will allow our users to continue getting reports while data is refreshing:
class ReportFeedback < ApplicationRecord
def self.refresh
Scenic.database
.refresh_materialized_view(table_name,
concurrently: true,
cascade: false)
end
end
We will need a unique index on one column for Postgres to support concurrent refreshing.
Step 2: Write the SQL query
We can now write our query in the newly generated db/views/report_feedbacks_v01.sql file:
SELECT feedbacks.id as id,
feedbacks.created_at as created_at,
feedbacks.positivity as positivity,
feedbacks.channel_id as channel_id,
channels.type as channel_type,
channels.name as channel_name,
(EXISTS (SELECT 1
FROM comments
WHERE comments.feedback_id = feedbacks.id
AND comments.customer_id IS NOT NULL)
) as has_comments
FROM feedbacks
INNER JOIN channels ON feedbacks.channel_id = channels.id
AND feedbacks.is_spam = false
AND feedbacks.created_at > (NOW() - interval '91 days')
In the migration file, we should add some indexes on those columns, including a unique index for concurrent refreshing:
class CreateReportFeedbacks < ActiveRecord::Migration[5.0]
def change
create_view :report_feedbacks, materialized: true
add_index :report_feedbacks, :id, unique: true
add_index :report_feedbacks, :created_at
add_index :report_feedbacks, :positivity
add_index :report_feedbacks, :channel_id
add_index :report_feedbacks, :channel_type
add_index :report_feedbacks, :channel_name
add_index :report_feedbacks, :has_comments
end
end
Now we can run the migration:
$ rails db:migrate
Step 3: Refresh the Data
As materialized views store the result of the query, we need to refresh the data on a regular basis. In our case it would not be reasonable to refresh the data on each new feedback: there are too many coming, and we would be constantly refreshing. So we went for a scheduled refreshing every 5 minutes, that means our Almost Real Time reporting has a delay of maximum 5 minutes, which is acceptable.
We are using the famous sidekiq gem for background jobs, as well as the clockwork gem for scheduled jobs. Let’s create a new worker and call it from lib/clock.rb:
# app/workers/report_refresh_worker.rb
class ReportRefreshWorker
include Sidekiq::Worker
sidekiq_options queue: "critical"
def perform(klass)
klass.constantize.refresh
end
end
# lib/clock.rb
# [...]
module Clockwork
# [...]
# Refresh Report Data every 5 minutes
every 1.hour, "report.refresh",
at: ["**:00", "**:05", "**:10", "**:15",
"**:20", "**:25", "**:30", "**:35",
"**:40", "**:45", "**:50", "**:55"],
tz: "UTC" do
ReportRefreshWorker.perform_async(ReportFeedback)
end
end
In Clockwork, we specify explicitly at what time to refresh. If we used every 5.minutes, it would trigger “report.refresh” on every app restart, which we don’t want.
When generating the matview for the first time, Clockwork might trigger a refresh with the matview not generated yet. The sidekiq job will fail. We can either kill it or wait for the migration to finish (if sidekiq is in retry mode).
Here it is, we now have a ReportFeedback model for a report_feedbacks Materialized View that can be queried with ActiveRecord:
ReportFeedback.where(channel_id: params[:channel_id])
.group(:channel_name)
.average(:positivity)
As the matview only contains the data for the last 91 days, we need a condition somewhere to either query the report_feedbacks matview, or the regular storing tables, depending on the requested time window:
class ReportingController
def positivity
if params[:from] > 90.days.ago
calculator = FastCalculator.new(params)
else
calculator = SlowCalculator.new(params)
end
render_success calculator.positivity
end
end
Benchmarks
The simplest reports have seen a 1x to 3x improvement:
Warming up --------------------------------------
real time: 1.000 i/100ms
mat view: 2.000 i/100ms
Calculating -------------------------------------
real time: 12.052 (± 8.3%) i/s - 120.000 in 10.024629s
mat view: 23.561 (± 4.2%) i/s - 236.000 in 10.055818s
Comparison:
mat view:: 23.6 i/s
real time:: 12.1 i/s - 1.95x slower
The reports with the most complex queries, who had a lot of sub-queries, have seen a 20x to 30x performance increase:
Warming up --------------------------------------
real time: 1.000 i/100ms
mat view: 1.000 i/100ms
Calculating -------------------------------------
real time: 0.285 (± 0.0%) i/s - 3.000 in 10.786589s
mat view: 7.540 (±13.3%) i/s - 75.000 in 10.018695s
Comparison:
mat view:: 7.5 i/s
real time:: 0.3 i/s - 26.41x slower
The difference is visible for our users:
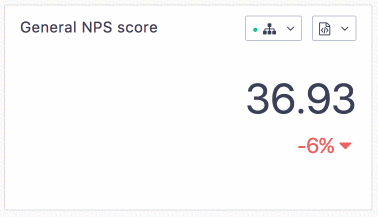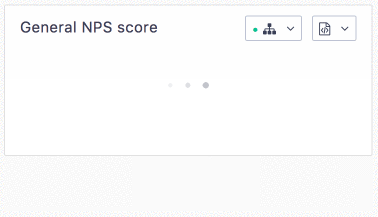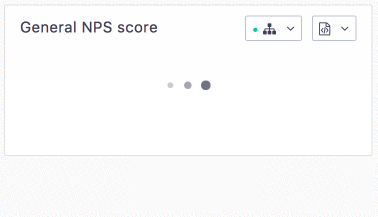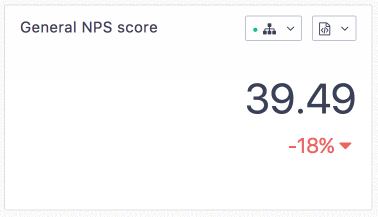
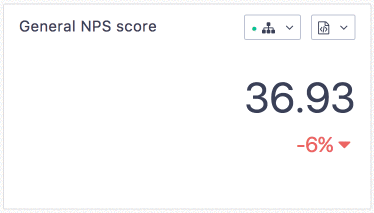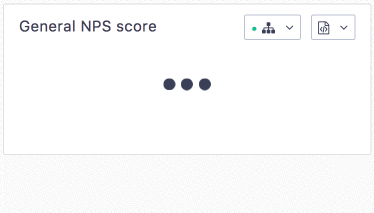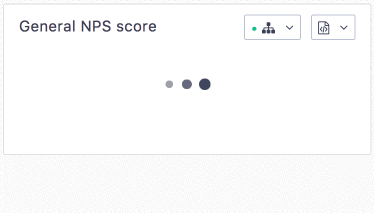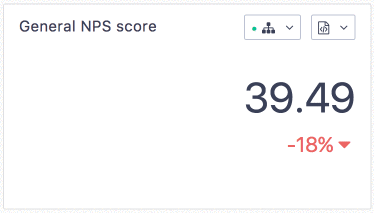
Conclusion
This solution with PG Materialized Views works great for us:
✅ Our performance is reasonable for our current need and 6 months projection. We already have plans for a second iteration with the same model that would increase performance even more when it’s needed.
✅ As we are already using PostgreSQL, it was very fast to learn how to create, update, destroy and refresh materialized views. Thanks to the great Ruby community, it’s even easier with the scenic gem. In total it took about 6 days of developer time altogether, from specs definition to having deployed the first iteration.
✅ Another great win compared to using another storage system is Data refreshing: It is one single PG instruction to refresh data in a materialized view. If we had to synchronize our Data in PostgreSQL to another storage system (like MongoDB for example), the synchronization job would be much more complex and prone to errors.
✅ There is nothing to maintain once everything is in place.